10 Oct CCI – Data Loading considerations with Partitioned Tables and CCI
Introduction
In this blog post, I would like to describe two case scenarios of bulk loading data, using SSIS, into a partitioned table that has a clustered columnstore index (CCI).
Let’s test the following two case scenarios:
- Bulk loading data from the source table directly into the partitioned table with a CCI.
- Bulk loading data from the source table into the staging tables (one staging table per partition) with clustered columnstore index followed by the partition SWITCH operation to the destination partitioned table with a CCI.
Test Case Scenario 1: Bulk Loading directly into the Partitioned Table with a CCI
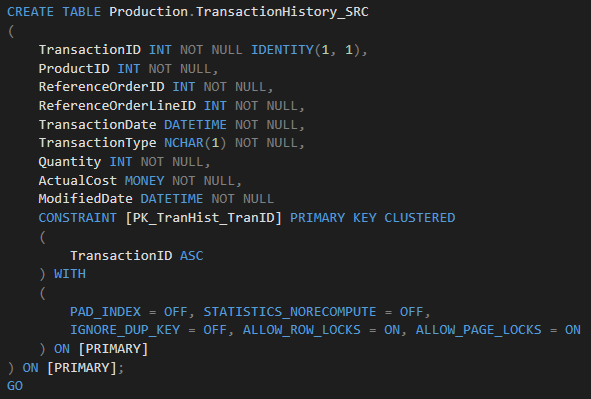
In this case scenario, we bulk load data directly from the source table named Production.TransactionHistory_SRC that contains 16 million records into the partitioned target table named Production.TransactionHistory_Part_DST that has a clustered columnstore index (CCI).
Here is the definition of the source table:
I have also created the following partition function and partition scheme:

We will be loading 16 million records from the source table into the 4 partitions (4 million records into each partition).
Note: The first partition where PartitionKey <= 0 will be empty as well as the last two partitions (where PartitionKey > 16 million and PartitionKey > 20 million).
The structure of our destination table looks like this:
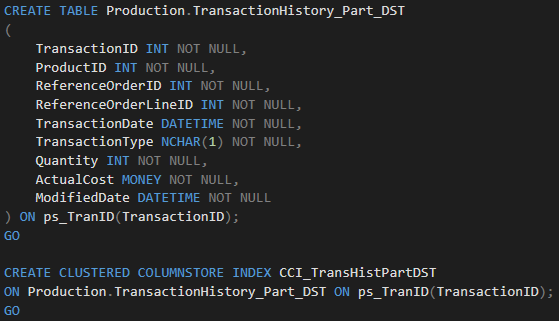
As the next step, I have created an SSIS package with a Data Flow task that loads data from the source table into the destination table.
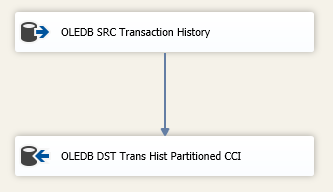
No doubt, it’s important to configure the SSIS Data Flow task properly. So here is the list of configuration changes that need to be done:
- Set the DefaultBufferSize, DefaultBufferMaxRows and AutoAdjustBufferSize properties:
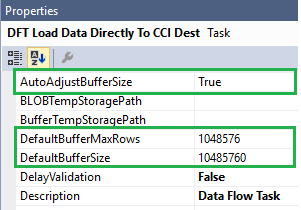
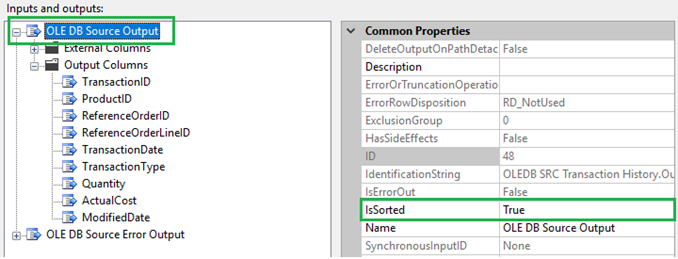
- Set the properties of the OLE DB Source Output to IsSorted = True (as our source is actually ordered by TransactionID ascending):
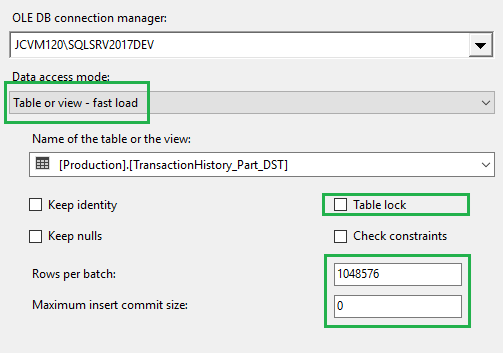
- Configure the OLE DB Destination component, so it’s optimized for loading CCI:
Let’s start the SSIS package. During the execution, we can observe an expensive and blocking sort operation in the Live Query Statistics – even if the OLE DB Source component has the option IsSorted set to True!

Obviously, the expensive Sort operation is also present in the actual execution plan:
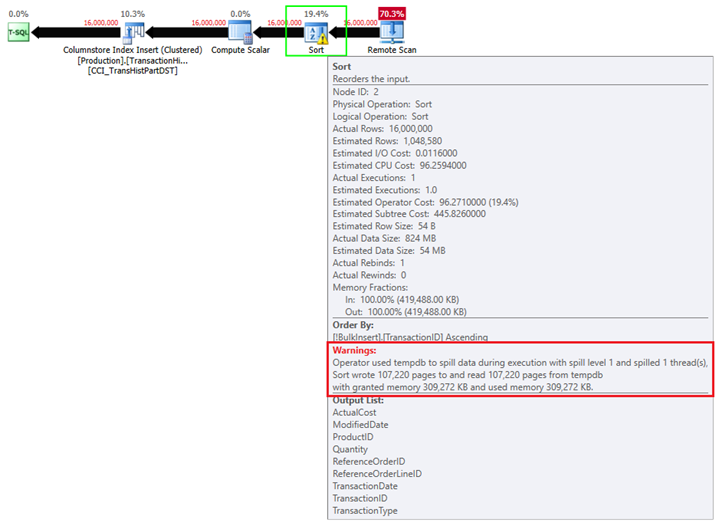
Honestly speaking, optimizer’s behavior is a bit surprising to me in this case scenario. On the other hand, this behavior is well explained in The Data Loading Performance Guide, which says:
“Bulk loading directly into a partitioned table will trigger a sort operation, even if there are no indexes on the table or the incoming data has an ORDERED hint. This sort operation is caused by the optimizer removing the overhead of continuously opening and closing new partitions under heavy insert activity.”
Test Case Scenario 2: Bulk Loading into Staging Tables followed by the SWITCH into the Partitioned Table with a CCI
As we can see, the first approach was not efficient enough, so let’s think about another way of loading data, ideally, without an expensive blocking Sort operation.
What if we bulk load data into the staging tables (each with a CCI) first, and perform the SWITCH operation into the destination table then?
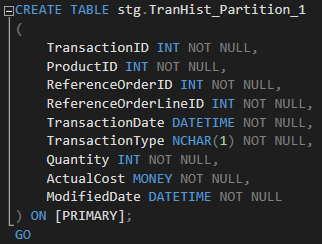
Here is the definition of our 4 staging tables (columns and data types are the same for all 4 staging tables):
And each staging table has a CCI index:

Obviously, the SSIS package needs to be slightly modified as we are going to load data into multiple staging tables now:
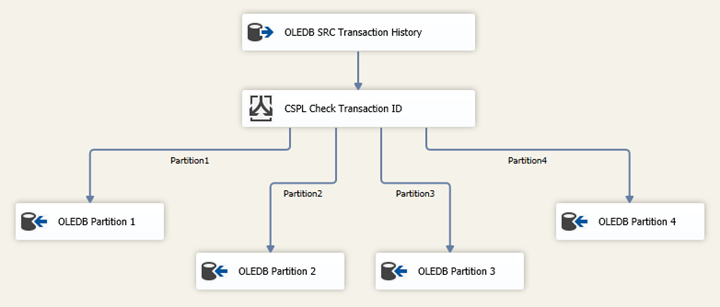
To distribute the data from our source to the staging tables, we use the Conditional Split component with the following conditions:
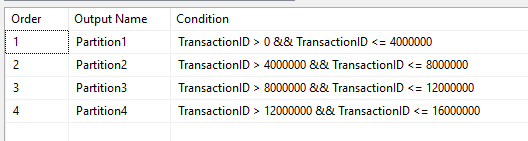
Note: Let’s keep the same settings for the OLE DB Source Component (IsSorted = True) and for all the OLE DB Destination components:
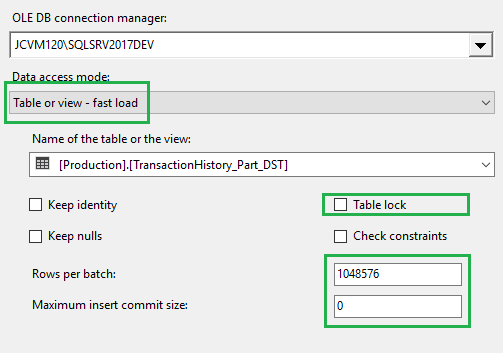
When we start the SSIS package execution and review the Live Query Statistics, the expensive blocking Sort operator is not present in the query plan anymore:
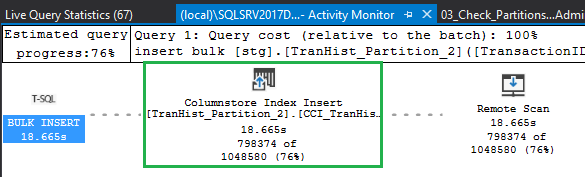
When we review the actual execution plan, Sort operation is indeed not present. Instead, we have a direct insert into the CCI for each of the staging tables:
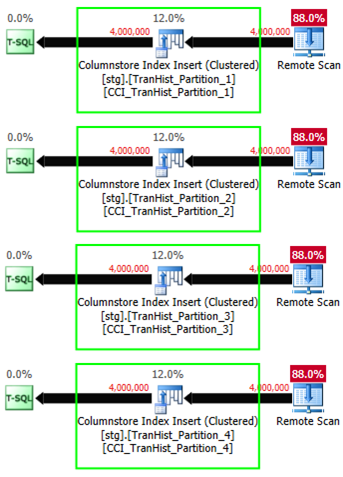
After we load 16 million records into the staging area, we will have to perform the partition SWITCH operation. But, before we do that, we must add proper CONSTRAINTS to each of the staging tables:
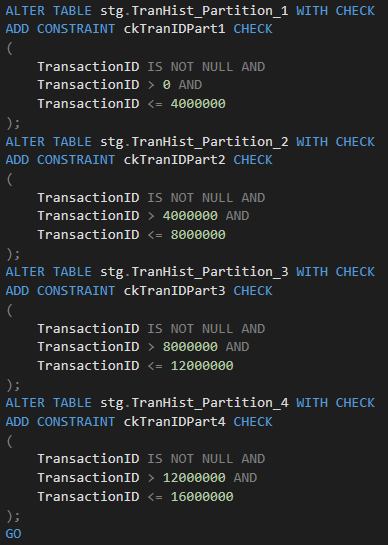
At this point we are all set to perform the partition switch operation:

We can go ahead and review the number of records in the destination table – 16 million

We can also review the destination table partitions, row count for each partition:
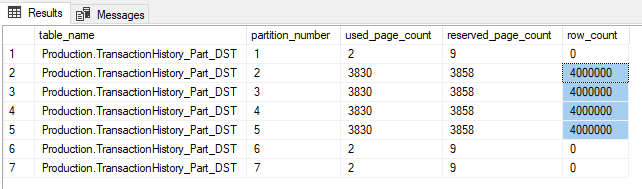
as well as the CCI row groups:
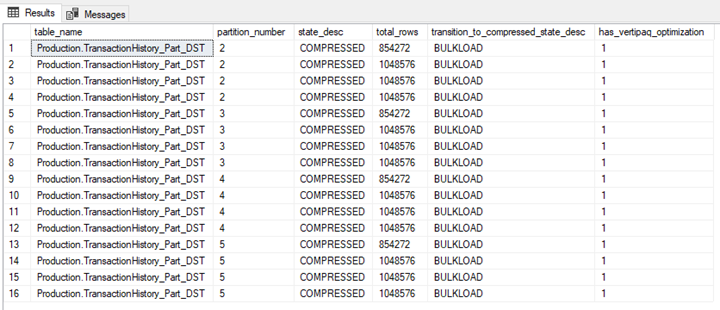
In the real world, the amount and definition of table partitions will change, and the conditions to split/distribute the data from our source to the destination will change over time so we need to make the solution more generic.
To make the solution more generic:
- partitions can be managed automatically (we can set up a scheduled job to create new partitions and remove the old ones),
- staging tables can be generated automatically (dynamic SQL),
- SSIS package (and the split conditions) can be also generated automatically using BIML.
Conclusion
Every time you are bulk loading data into a (partitioned) table that has a CCI, ensure your SSIS package is configured properly.
Bulk loading directly into a partitioned table will trigger an expensive and blocking sort operation, even if there are no indexes on the table or the incoming data has an ORDERED hint.
One of the options for avoiding the blocking Sort operation when bulk loading data into the partitioned table with a CCI is to:
- create staging tables,
- load data into the staging area,
- add proper constraints to the staging tables,
- perform the SWITCH operation into the destination table with a CCI.
Sources
https://docs.microsoft.com/en-us/previous-versions/sql/sql-server-2008/dd425070(v=sql.100)
Sorry, the comment form is closed at this time.